前言
字符是我们编写程序的基础的基础。
我们前端是最常见的字符,符号,数字,英文,中文, 我们通常都是使用直接量来表示,偶尔会在正则表达等场景用到UTF-16码点的格式,问题来了,那你知道JS有几种字符表示方式吗?
答案:至少6种,以字符a为例子:
`a`
'a'
'\a'
'\141'
'\x61'
'\u0061'
'\u{0061}'
前三种都很理解, 后面这又是\, \x, \u, \u{}, 这都是什么玩意?
特别申明: 测试代码最新版chrome上执行。
先看总结
| 格式 | 示例 | 码点范围 | 注意 |
|---|
| \8进制 | '\141' | 0-255 | 模板字符串中不可直接使用 |
| \x两位16进制 | '\x61' | 0-255 | 必须两位 |
| \u四位16进制 | '\u0061' | 0-65535 | 必须四位 |
| \u{16进制} | '\u{0061}' | 0-0x10FFFF | 码点大于0xFFFF,length为2,下标访问值是高低位的值 |
编码基础知识
完全理解字符表示,还是需要一些简单的编码知识,我们一起来看看吧。
ASCII 码
ASCII 码一共定义了 128 个字符,例字母 a 是 97 (0110 0001)。这 128 个字符只使用了 8 位二进制数中的后面 7 位,最前面的一位统一规定为 0。
ASCII 码止共定义了128个字符,其中33个字符无法显示。0010 0000 ~ 0111 1110 (32-126)是可以显示的 ,基本都能使用键盘打出来, 具体参见对照表: ASCII编码对照表。
ASCII 额外扩展的版本 EASCII,这里就可以使用一个完整子节的 8 个 bit 位表示共 256 个字符,其中就又包括了一些衍生的拉丁字母。 可以参见 extended-ascii-table。
Unicode 和 码点
Unicode是字符集, 为了兼容ASCII,Unicode规定前0-127个字符是和ASCII是一样的,不一样的是128-255这一部分。
我们一起看看ASCII 128-255部分:
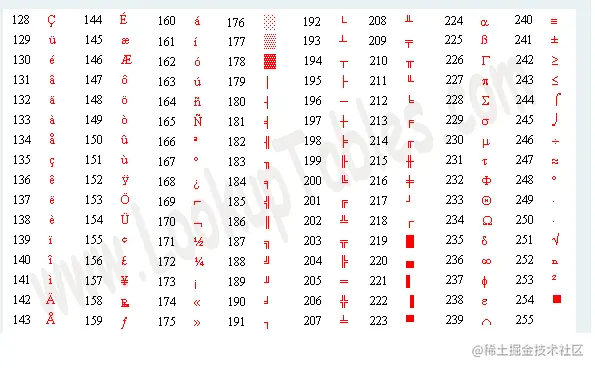 再看看 Unicode的 128-255部分:
再看看 Unicode的 128-255部分:

其给某个字符规定对应的数值,我们经常称其为码点。我们可以通过字符串的实例方法charCodeAt和codePointAt获取,前者只能准确获取码点值小于0xFFFF(65535)的码点。
'𠀠'.codePointAt(0)
'𠀠'.charCodeAt(0)
'a'.charCodeAt(0)
对应的我们可以使用String的静态方法fromCharCode,fromCodePoint用码点获取对应的字符。
String.fromCodePoint(131104)
String.fromCharCode(131104)
String.fromCharCode(97)
UTF-8, UTF-16
我们平时接触比多的就是UTF-8和UTF-16,均是Unicode字符编写的一种实现。 我们JS编码的字符串是UTF-16格式来存储的和表示的。
UTF-16对于码点小于0xFFFF的用2个字节(1个编码单元)表示,大于0xFFFF的编码用四个字节(2个编码单元)表示。 具体的体现可以表现在字符的长度上。
"𠀠".length
"a".length
"人".length
这里强调 0xFFFF 是分界线,很重要。
进制转换
我们可以使用数字实例toString()10进制转为相对应的进制。
97..toString(16)
97..toString(2)
下面进入正题, 一起来看字符的表示:
\ + 字符
\ 是一个特殊的存在,转义字符,大多数情况下,不产生什么作用。 只对一些特殊的字符起作用。
从下可以看出\a这个\没有任何作用,对\r就不一样了。

更多转义字符知识,参见 转义字符-维基。
\ + 八进制
其能表示的码点范围值为 0-255。
这里提个问题, 这里显示的ASCII的字符,还是Unicode的字符。
- 比如字符
a 为 97, 可以使用charCodeAt获取,
'a'.charCodeAt(0)
- 转为8进制为
97..toString(8) = 141 \141
console.log('\141')
我们看一些特殊码点的字符,因为码点为31和127的字符,不能被显示或者表示。
'\37'
'\177'
至于为什么 \177 变为了 \x7F, 是不是有点疑惑,其实也很简单。 当程序检查其值,不在可显示范围的时候,直接反向计算其原值,并转为16进制值,并使用\x两位十六进制格式表示。
'\177'
127.toString(16)
关于表示码点上限(255):
'\377'
'\400'
回答开始的提问:
我们这里显示的肯定是Unicode字符啊,前面提过了, JS字符编码采用的是UTF-16啊。 可以用码点在128-255的一个字符试试, 那就码点254的字符吧:
扩展 ASCII 254: 
Unicode 254: 'þ'
'\376'
所以大家要明白,我们这各种字符表示方法,表示的都是Unicode字符。
关于\x两位十六进制格式,我们开讲。
\x + 两位十六进制
我们可以用0x表示16进制的数字,所以\x大家也很好理解,是16进制。
0x61
'a'.charCodeAt(0)
97..toString(16)
'\x61'
两位十六进制码点, 0x00 ~ 0xFF(0~255) , 和 \八进制码一样,不可显示的码点字符,直接显示其编码
'\x1F'
'\x20'
'\x7e'
'\x7f'
'\x80'
到这里你可能问,你这里,那么这不能显示,那不能显示,有没有一个表啊。有的, 参见 Unicode码表, 这里记录了 0x0000 到 0xFFFF的码点的字符,一般情况准够用。
0-255码点范围内, 0x00 到 0x1F(0-31), 0x80 到 0x9F(128-159)是无法显示的或者看不见的。 
'\x9F'
'\xA1'
这个结果,在不通浏览器,可能输出还不一样。 尽量采用最新版本的chrome去验证。
虽然输出的显示有些区别,但是都表示这玩意不能表示一个字符,请自重。
360浏览器:

firefox:

chrome:

\u + 四位十六进制
这里固定是4位,少一位都不行。
"\u0061"
"\u061"
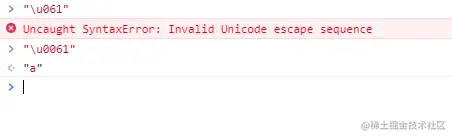
还是4位,如果多了, 截取前4位,后面的直接追加。看个例子,非常好理解。
'\u0061'
'\u00610'
这里也就反应了问题,码点大于0xFFFF,大于4位16进制的字符怎么表示???
ES6考虑了这个问题,于是推出了 \u{ + 十六进制 + }, 看下个章节。
我们之前说过,UTF-16是Unicode的一种实现,Unicode的代理区 0xD800-0xDFFF, 其不代表任何字符。同理,我们采用\u + 四位十六进制方式,如果码点在这个区间,返回 �或者原字符(浏览器不同,可能返回不同), 当然其他的码点也可能还没设定值或者是不可打印的。
'\uD800'
'\uDFFF'
实际上 UTF-16也就是利用了代理区,把码点大于0xFFFF字符分为高低两部分, 索引值0获得的值实际上是高位部分,索引值1获得的是低位部分。
var text = "𠀠";
text[0]
text[1]
更多utf-16编码的知识,我们后续跟上。
\u{ + 十六进制 + }
ES6新增的能力。 这个多了一个{}包裹。
这个应该是可以一统江湖,可以表示码点低于0xFFFF的字符,也可表示码点大于0xFFFF的字符。
"\u{20020}"
"\u{0061}"
"\u{061}"
"\u{61}"
"\u{9}"
而且其还没有强制四位的限制,简直爽的没法没边。
缺点嘛,那就是兼容性了,就让时间去磨平吧。
ES6的模板字符串
ES6的模板字符串,可以说是爽歪歪,我们就也算其一种新的字符表示方式吧。
我们也是可以使用\u, \u{}, \x格式的
`我\u{61}`
`我\x61`
`我\u0061`
`我\a`
到这里,你们没觉得少了了点什么吗? 没错 \8进制,是不被允许的
`我\141`

如果,你非得用,那就 ${''}包裹一下:
`我${'\141'}`
实际的应用
匹配中文的正则
我们总不能去罗列,多义采取的是[\u4e00-\u9fa5]这种格式去匹配:
var regZH = /[\u4e00-\u9fa5]/g;
regZH.test("a");
regZH.test("人");
regZH.test("𠀠");
这里注意了,只能识别常见中文。, 毕竟码点的范围就那么大点。
去掉空白字符
看看MDN上 String.prototype.trim
if (!String.prototype.trim) {
String.prototype.trim = function () {
return this.replace(/^[\s\uFEFF\xA0]+|[\s\uFEFF\xA0]+$/g, '');
};
}
我们一起来看一下著名的core-js对trim的空白字符的理解 whitespaces.js
module.exports = '\u0009\u000A\u000B\u000C\u000D\u0020\u00A0\u1680\u2000\u2001\u2002' +
'\u2003\u2004\u2005\u2006\u2007\u2008\u2009\u200A\u202F\u205F\u3000\u2028\u2029\uFEFF';
我们还是输出一下吧:
'\u0009\u000A\u000B\u000C\u000D\u0020\u00A0\u1680\u2000\u2001\u2002' +
'\u2003\u2004\u2005\u2006\u2007\u2008\u2009\u200A\u202F\u205F\u3000\u2028\u2029\uFEFF'
'
CSS content属性 和 CSS 字体图标
现代浏览器,已经支持中文,但是建议还是使用\16进制编码格式 。
这里使用的是 \16进制, 不需要u也不需要{}, 支持码点大于0xFFFF的字符
div.me::before {
content: "\6211"; // 我
padding-right: 10px;
}
div.me::before {
content: "\20020:"; // 𠀠
padding-right: 10px;
}
CSS颜色色值
字体颜色,背景颜色,边框颜色等等,其有一种表示方式就是6位16进制,当然也有简写形式。
.title {
color: #FFF
}
字符个数统计
这个是利用了UTF-16编码特性。 因为\uD800-\DFFF是代理区,具体UTF-16编码的东西,单独来讲解。 也可以看见文章 为什么一定是�, 里面有完整的解释。
const spRegexp = /[\uD800-\uDBFF][\uDC00-\uDFFF]/g;
function chCounts(str){
return str.replace(spRegexp, '_').length;
}
chCounts("𠀠")
"𠀠".length
ES6中的方式就多一些了:
Array.from("𠀠").length
[..."𠀠"].length
文件类型识别
具体可以参见阿宝哥的 JavaScript 如何检测文件的类型?
const isPNG = check([0x89, 0x50, 0x4e, 0x47, 0x0d, 0x0a, 0x1a, 0x0a]);
const realFileElement = document.querySelector("#realFileType");
async function handleChange(event) {
const file = event.target.files[0];
const buffers = await readBuffer(file, 0, 8);
const uint8Array = new Uint8Array(buffers);
realFileElement.innerText = `${file.name}文件的类型是:${
isPNG(uint8Array) ? "image/png" : file.type
}`;
}
其他
- emoji图标
- 编码转换,比如utf-8转base64
- 等等
转自https://juejin.cn/post/7033184851494699022
该文章在 2025/2/19 10:33:51 编辑过






 400 186 1886
400 186 1886


